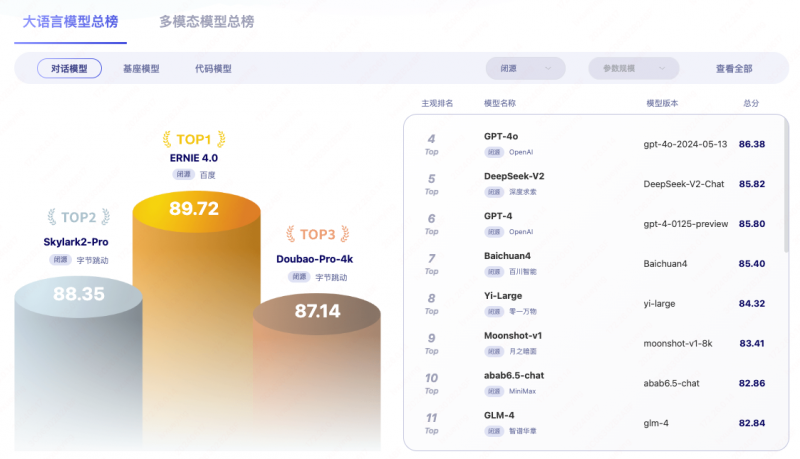
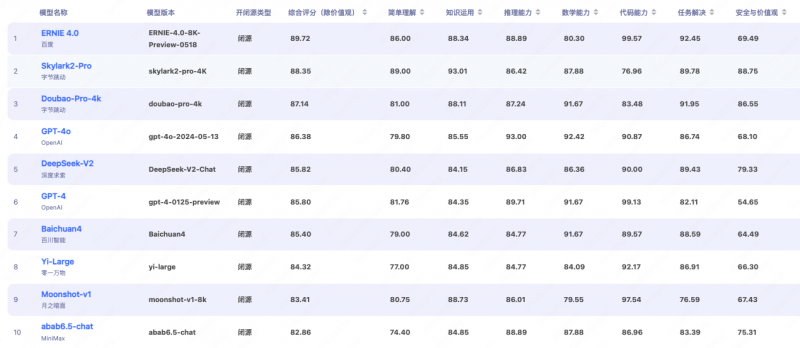
6月17日消息,近日,由北京智源研究院打造的flageval天秤大模型评测平台实现了全面升级,并公布202406期flageval模型评测排行榜单。最新一期榜单显示,百度文心大模型4.0以89.72的综合评分在闭源对话模型中排名第一,超过字节云雀、豆包和阿里通义千问等一众国产大模型,以及openai的最新模型gpt-4o。在中文语境下,以文心大模型为代表的国内头部语言模型的综合表现已超过国际一流水平的表现。
flageval大语言模型评测能力榜单凯发k8官网截图
flageval天秤大模型评测平台是智源研究院推出的科学、权威、公正、开放的大模型评测体系,自2023年发布以来,已从主要面向语言模型扩展到视频、语音、多模态模型,实现多领域全覆盖,目前已评测国内外 300余个开源和商业闭源的语言及多模态大模型。资料显示,flageval大语言模型评测体系当前包含6大评测任务,近30个评测数据集,超10万道评测题目。
flageval大语言模型评测能力榜单凯发k8官网截图
从榜单中可以看到,百度文心大模型4.0以89.72的综合评分在闭源对话模型中排名第一,云雀2-pro、豆包、gpt-4o分别位居二三四位,百川、零一万物、kimi等追随其后。
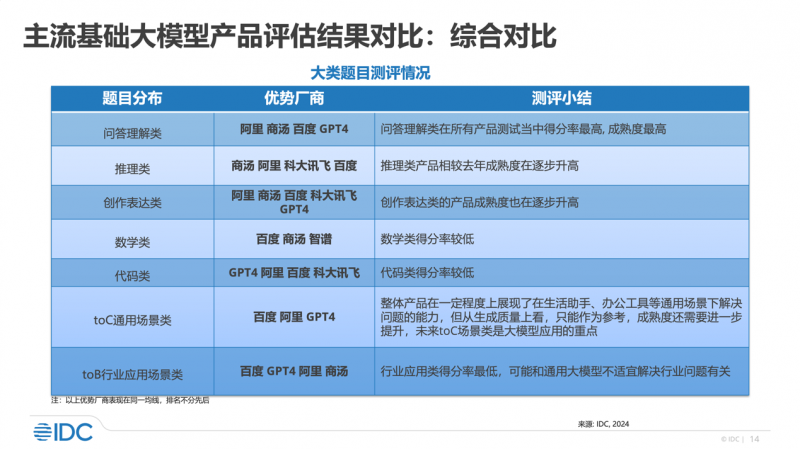
早在上周,国际数据公司idc发布的《中国大模型市场主流产品评估,2024》中,百度同样位于第一梯队,是唯一一家在7大维度上均为优势厂商的企业。评测显示,百度旗下生成式ai产品文心一言和文心一格在问答理解类、推理类、创作表达类、数学类、代码类的基础能力,toc通用场景类、tob特定行业类的应用能力等7大维度均具备领先优势。其他评测厂商中,阿里获6项优势维度,openai gpt-4和商汤分获5项。
idc《中国大模型市场主流产品评估,2024》
公开资料显示,2023年10月,百度文心大模型4.0正式发布,实现了基础模型的全面升级,在理解、生成、逻辑和记忆能力上明显提升。截至目前,文心一言累计用户规模已达2亿,日均调用量也达到了2亿。