· yandex推出yafsdp,这是一种更快、更高效的大语言模型(llm)训练方法。
· yafsdp最高加速达到26%。这种针对图形处理器(gpu)消耗的优化使开发人员和企业每月可节省数十万美元。
· yafsdp是目前改善图形处理器通信和减少内存使用的最有效方法。
· yafsdp方法可以在github上免费获取。全球的机器学习(ml)工程师和企业可以使用它来提高大语言模型训练效率。
全球科技公司yandex最近推出了yafsdp,这是一种用于训练大型语言模型(llm)的开源方法。
yafsdp是目前在大型语言模型训练中增强图形处理器(gpu)通信并减少内存使用量的公开可用的最有效工具,与fsdp相比,根据架构和参数数量,其速度最多可提高26%。通过使用yafsdp缩短大型语言模型的训练时间,可以节省高达20%的图形处理器资源。

yandex公司高级开发人员、yafsdp开发团队成员米哈伊尔·赫鲁晓夫(mikhail khruschev)表示:“目前,我们正在积极试验各种模型架构和参数大小,以扩展yafsdp的多功能性。我们很高兴能与全球机器学习社区分享我们在大型语言模型方面的成果,为提高全球研究人员和开发人员的可访问性和效率做出贡献。”
yafsdp案例
大型语言模型训练是一个耗时且资源密集的过程。在大型语言模型训练期间,开发人员必须有效管理三种主要资源:计算能力、处理器内存和处理器通信。自行开发大型语言模型的机器学习工程师和企业会投入大量时间和图形处理器资源来训练这些模型。模型越大,与其训练相关的时间和费用就越多。
需要说明的是,大型语言模型训练依赖于组织成集群的众多图形处理器,这些集群是互连的图形处理器阵列,可以执行训练具有数十亿参数的模型所需的大量计算。在集群内的处理器之间分配计算需要持续的通信,这往往会成为“瓶颈”,减缓训练过程并导致计算能力的低效利用。
为了克服这一瓶颈,yandex开发人员创建了yafsdp,优化了学习速度和性能,通过消除图形处理器通信效率低下的问题,确保了训练时仅需要关注必要的处理器内存,并使图形处理器交互不受干扰。这也使全球人工智能开发人员在训练模型时能够使用更少的计算能力和图形处理器资源。例如,在涉及一个具有700亿参数的模型的预训练场景中,使用yafsdp可以节省大约150个图形处理器的资源,这相当于每月节省大约360万至1080万元人民币(取决于虚拟图形处理器提供商或平台)。
yafsdp的训练效率
yafsdp是fsdp的增强版本,在大型语言模型训练中通信最密集的阶段,如预培训、对齐和微调,均优于fsdp方法。yafsdp在llama 2和 llama 3上显示的最终加速结果表明,其训练速度有了显著提高,在 llama 2 70b和llama 3 70b上分别达到21%和26%。当与yandex的其他性能增强凯发k8官网的解决方案结合使用时,该方法可将某些模型的训练过程加速高达45%。
“yafsdp在13至700亿个参数的模型上显示了令人印象深刻的结果,在30至700亿个参数范围内的表现尤为强劲,”米哈伊尔·赫鲁晓夫表示,“目前,yafsdp最适合基于llama架构的广泛使用的开源模型。”
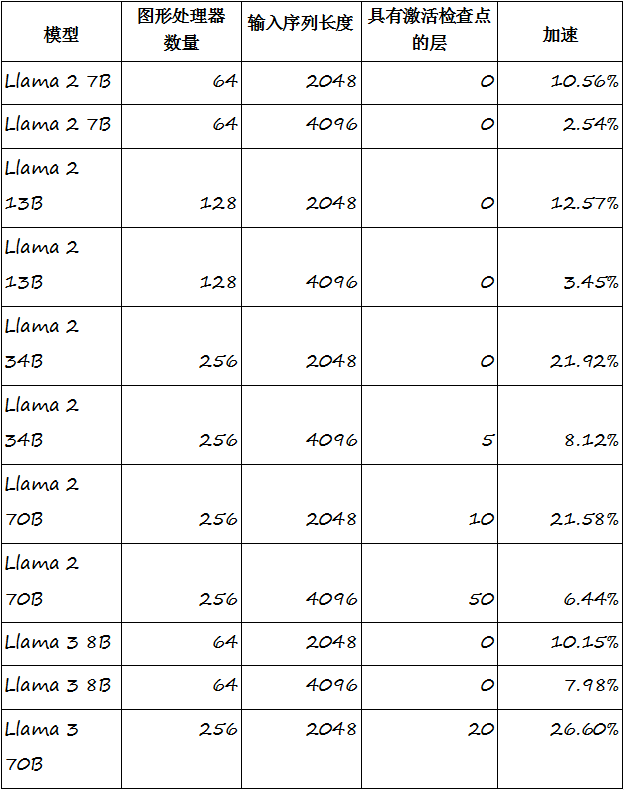
图: yafsdp方法可以有效地用于基于转换器的多层文本生成模型(多层感知器),这些模型大多以类似 llama的模型为代表。在700亿参数模型的预训练场景中,使用yafsdp可以节省约150个图形处理器的资源。
yafsdp并不是yandex的第一个开源工具。该公司此前曾分享过其他几款在机器学习社区中备受欢迎的工具,包括:
· catboost,一个用于决策树梯度提升的高性能库。
· ytsaurus,一个分布式存储和处理的大数据平台。
· aqlm,用于大型语言模型极端压缩的最先进的量化算法之一,由yandex research、俄罗斯国家研究型高等经济大学(hse university)、奥地利科学技术研究所(ist austria)和neuralmagic联合开发。
· petals,一个旨在简化大型语言模型训练和微调过程的库,由yandex research、俄罗斯国家研究型高等经济大学、华盛顿大学、hugging face、ens巴黎-萨克雷分校和yandex数据分析学院合作开发。