7月6日,以“智见未来,护航ai”为主题的2024网易易盾ai数字内容风控大会在杭州顺利举行。会上,网易数智旗下网易易盾正式发布面向数字内容风控领域的安全大模型。
"安全是一个需要抬头创新、低头深耕的行业。数字内容风控这个网络安全领域内的细分赛道正在蓬勃发展,这次安全大模型的发布是我们多年来技术和经验沉淀的‘集大成时刻’。”网易数智副总经理、网易易盾总经理朱浩齐在大会上带来网易易盾自研安全大模型的首次正式亮相。

七年磨一剑:为安全范式转变做准备
在社会学著作《理解媒介》中,思想家麦克卢汉曾深刻、具体地揭示了媒介的影响力。
按照麦克卢汉的理论,媒介信息在很大程度上影响人间事物的尺度变化和模式变化,塑造人的组合方式和形态。因此,媒体是导致社会变动的最强大力量之一。从报纸到电视广播,再到网络传媒与数字时代的新媒体,作为信息和内容的载体,媒介方式随着技术变革在不断进化。与此同时,麦克卢汉的理论在逐步得到证实。
数字内容的安全问题不仅没有随着技术进步消除,相反,对社会的影响正在逐年上升。
“我们在经历一场底层安全范式的转变。信息传播技术的进步把内容安全问题的重要性升级了,需求端从原先的附加安全发生了到内生安全这一模式转变。作为服务者,我们不仅需要从理论、技术和工具上做准备,更需要从思维上主动拥抱变革。”朱浩齐在大会上说。
如今,人工智能技术的发展与应用极大地提升了内容生产的效率和质量。通过自然语言处理(nlp)、机器学习、图像识别等技术,人工智能可以帮助企业自动化地生成文章、视频、图像等内容,甚至进行个性化推荐和优化,满足用户的多样化需求。诚然,aigc为企业与社会带来内容生产力的成倍增长,但也再次放大数字内容安全的重要性。
从最开始服务于网易内部业务的安全部门到服务外部客户的完全商业化品牌,网易易盾既有天然的技术优势,又有丰富的的场景实践经验。
同时,多年内外部客户的持续服务也让网易易盾拥有了成熟的技术、产品与服务体系。网易易盾面向娱乐社交、游戏、电商、金融、零售、政企等多个行业相继推出了凯发k8官网的解决方案,同时秉持“助力客户内生成长”的服务理念,持续上线aigc内容安全、出海安全合规、未成年人网络保护等数十个场景化安全方案。
7年多的时间,网易易盾累计数据检测量超3万亿,覆盖终端数超32亿,服务客户审核效率提升超10倍。
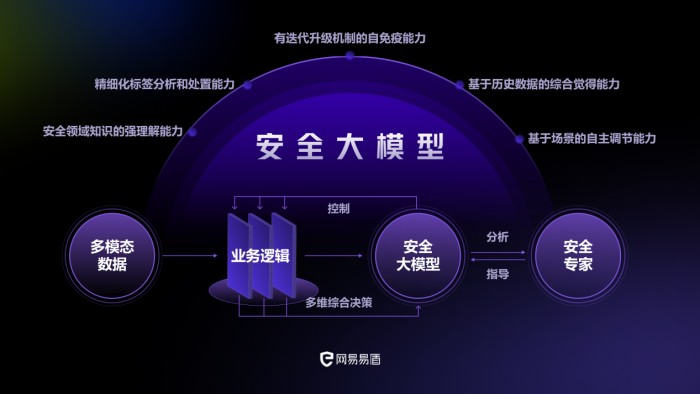
网易易盾既是数字内容风控领域的头部企业,又是ai时代的先行者。率先参与到从附加安全到内生安全的转变,并以ai技术为安全业务赋能,给客户提供更加专业的安全产品和服务,进而推动行业发展——这在网易易盾总经理朱浩齐看来,是义不容辞的责任,也是得天独厚的市场先机。
因此,更懂数字内容风控的安全大模型正式发布了。
安全大模型:聚焦数字内容风控
在数字内容安全问题治理的过程中,过去很长一段时间,更多的是凭借经验。
在抖音上这句话能不能发?在小红书上这个问题能不能搜到?在微博这个话题是否可以讨论?然而落到个体对每次具体情况的理解不同,最终体现在安全风控措施的理解上也非常不同。
在网易易盾成立的初期,曾有过一次深入的讨论:我们能不能基于我们对各行业实际落地的经验,去建立各行业内容风控的标准?而在实际落地过程中,发现标准仍还是非常的粗糙,与以往并没有根本性不同。
大模型的兴起和应用,使网易易盾这个想法真正具备可行性。早在2021年,网易易盾就开始着手研究大模型相关技术,通过让大模型学习理解不同场景下,不同内容的评判结果,让人工智能去建立各行各业、各个场景中内容风控的研判标准,进而完成数字内容的精细化治理。
在这样复杂的特定场景中,通用大模型显然并不能提供符合需求的最优解。
“数字内容风控是安全服务。安全,就要一丝一毫都不能差。我们给客户提供的必须是我们自己都挑不出问题的完美方案。”朱浩齐讲述了带领团队开发安全垂直大模型时的原则和思路。
在大模型的“军备竞赛”中,网易易盾虽然有“行业领军者”的自我要求,却不急于将不够完美的产品推向客户。基于自身业务的特性,从客户的需求和实际应用场景出发,再到小心翼翼地验证产品的每一个功能细节,直到反复确认没有问题,可以解决客户的问题——网易易盾的大模型之路走的每一步都是稳字当先。

应用安全大模型的数字内容风控通过大模型对风控尺度的理解,对风险内容实现标签的自动、精准标识,提升人工审核效率。目前,基于各种场景的测试情况,网易易盾安全大模型已经做到对部分色情疑难样本召回提升30%以上,助力广告对抗场景下的违法广告识别率达到97%以上,aigc人脸风格化疑难案例的识别率超90%。此外,该安全大模型将风险对抗的时效提升到了小时级,并且辅助真人引流团伙检出量增长达3倍。
同时,在结合了网易易盾安全大模型的通用大模型问答场景中,基于安全大模型对用户输入的语义理解和对风控规则的理解,能够帮助各类通用大模型对于一些“看上去不好答”的题目,给予准确的回答。除少数几个极度敏感的议题外,帮助提供开放式问答的模型能够快速做到“应答尽答”。
以“模”治“模”:ai时代的长远蓝图
生成式人工智能的发展始终伴随着对安全的质疑。
自chatgpt引爆人工智能浪潮热点后,世界各国纷纷紧急将生成式人工智能的安全管控上升至重要紧急议题。我国为了促进生成式人工智能健康发展和规范应用,发布《生成式人工智能服务管理暂行办法》,欧盟理事会批准全球首部对人工智能进行全面监管的《人工智能法案》,美国发布一项名为关于安全、可靠和值得信赖的人工智能(ai)的相关行政令。
综合世界各国政府部门与顶级智库对于人工智能安全问题的判断来看,大模型时代的安全面临突出的问题在于数据安全、内容安全,其中包括业务安全、供应链安全、合规以及道德伦理风险。
其中,在当下以及未来很长一段时间内,内容安全问题会一直是人工智能治理的关键挑战。社会需要关注的是大模型生成,如ai换脸的虚假违规内容被利用为作恶工具,以及幻觉问题、知识模糊、不实新闻等。
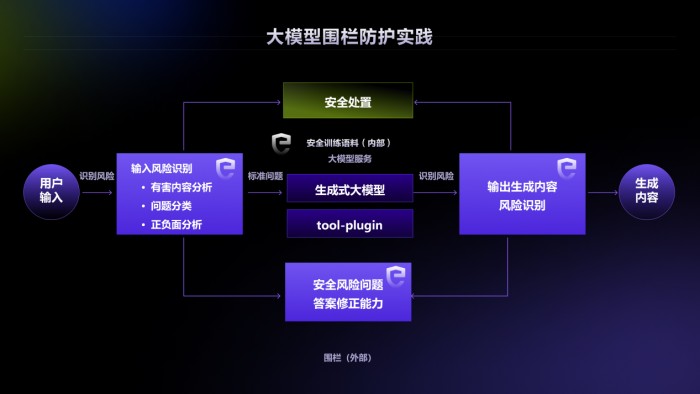
“对人工智能的治理,长期来看,也许需要靠另一个人工智能了。”朱浩齐表达了对ai时代内容安全问题治理趋势的判断,“人工智能给数字内容生产和传播效率带来的是几何倍数级别的增长,对于安全治理的能力提升要求自然也只有人工智能才能满足。”
安全,不是一朝一夕的事情。尤其是全新技术带来的既有“已知的未知”安全问题,也有“未知的未知”安全问题。为了解决各种“已知的未知”和“未知的未知”安全问题,网易易盾在大模型的研发思路中应用了新设计的防御理论:内生的弹性纵深防御体系。这个体系中有两个最重要的设计原则:
一是用时间换精度。这个原则中考虑的并非某个时间点下系统的静态防御能力,而是需要评估在持续的攻击之下系统的自我升级能力,其称之为“自免疫力”。
二是用不确定性提升防御强度。在测试数据变化的情况下,该原则要求通过提升自我保护能力实现系统对多次攻击的稳定防御。
用大模型治理大模型的数字内容安全,用人工智能对抗人工智能带来的安全风险。这是网易易盾对未来趋势的判断,也是网易易盾正在走的安全技术长征。