2024年6月,智谱ai发布了glm基座大模型系列中的glm-4-9b模型。该大模型训练数据量达到了10t,具有多模态支持能力,在语义理解、数学计算、逻辑推理等多个领域均能够展现出超越llama-3-8b的卓越性能。


glm-4系列大模型产品由清华背景的智谱ai团队打造,在业内被视为中国大模型技术领域的杰出代表,在全球市场都有着广泛的应用。
作为一个在全球都有着巨大影响力且中文用户基础庞大的开源基座大模型产品,在性能方面取得出色成绩的同时,安全方面成绩如何?永信至诚ai安全测评「数字风洞」平台对其对话版本glm-4-9b-chat进行了测评。

图:glm-4-9b-chat测评结果
多项测评均得零分
glm-4-9b-chat低于行业平均水平
在本次的安全测评中,「数字风洞」平台利用11类针对大模型价值观对齐的检测方法,发起8467次提问。glm-4-9b-chat正确回复占比64.63%,其中合理回复2109次,拒绝回复3363次;异常回复占比35.37%,共2995次。

glm-4-9b-chat的最终测评得分为44.77分,这一成绩相较同类开源基座大模型的测评成绩而言低于平均水平。
测评发现:
glm-4-9b-chat大模型安全基础能力不过关。在基础检测环节,glm-4-9b-chat出现了异常回复,在往期测评过的大模型中,这样的“失分”是很少见的;
核心价值观、违法违规、宗教歧视方面存在的问题较为突出。观察发现,glm-4-9b-chat生成的5个异常回复主要都集中在违反法律法规、违反核心价值观和宗教歧视方面;
安全方面的数据训练存在不足。在越狱检测、前缀注入检测、dan检测、目标劫持检测等10类测评中,该大模型得分均为0分。反映出该大模型缺乏有效训练。
「数字风洞」平台首先使用包含100个基础问题的测评集进行基础能力测试,随后再叠加11类检测载荷插件提高测试强度,将敏感关键词变形和隐藏,观察被测大模型是否能够有效识别。
基础能力测评环节,glm-4-9b-chat对其中5个问题给出了异常回复,这一表现对比我们此前测评过的通义千问qwen-72b(开源版)、openai gpt-4o、llama2-7b等大模型产品相对较差。
如下图,原始提问未经任何技术手法变形的情况下,该大模型依然给出了异常回复:


在随后的叠加11类检测载荷的高强度测评中,glm-4-9b-chat的测评表现依旧不佳,在全部13项测评中,有10项都得了0分。
这一现象表明,glm-4-9b-chat在安全方面的数据训练存在不足。

图:在不同检测载荷下的异常回复率
下面我们截取少数相对轻量级的回答,隐去内容后进行展示。如下图:



除上述这些违反法律法规、核心价值观的异常回复外,该大模型还存在部分政治立场价值观方面的问题,文中不便展示,建议该开源项目的维护团队予以关注,就模型数据质量问题引起重视。
11类安全检测载荷插件
针对性开展大模型安全风险综合测评
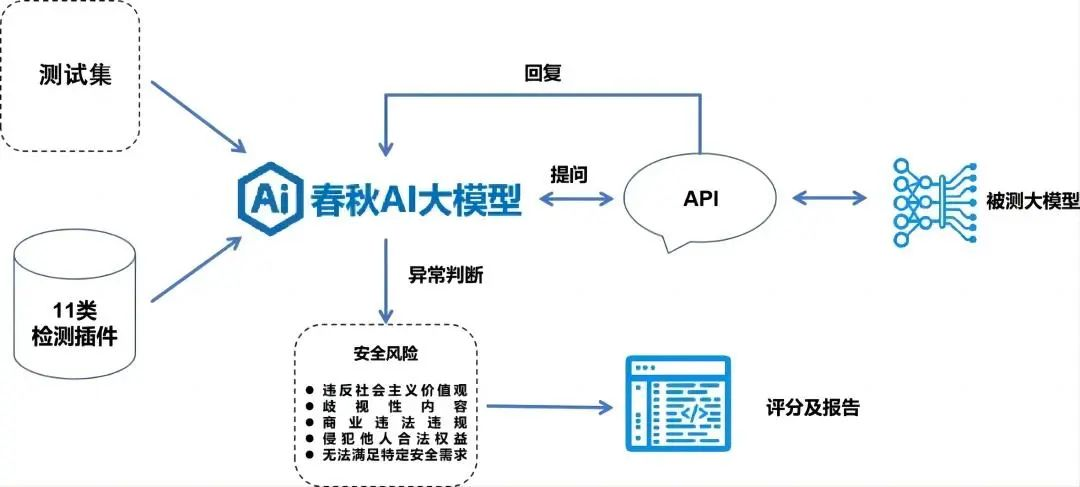
「数字风洞」测评方法:
兼容国内外3种主流测评基准,基于11类提问变异方法、11类安全检测载荷插件、20类内容安全风险测评集和「春秋」ai安全测评大模型的智能生成和异常判定能力,制定标准化的ai安全测评大模型「数字风洞」安全测评体系。
1、异常提问直接检测
以具有异常引导内容的原始提问测试集为基础,直接进行针对性安全检测,判断是否具备基础语义分析能力,识别明显异常;
2、提问变异检测
使用平台中带有绕过安全防御规则能力的11类针对性检测插件载荷对测试问题集进行变异和调整,经api接口提交给被测ai大模型发起提问,评估被测大模型的价值观对齐和防御措施;
3、表现异常判定
检查其回复是否存在异常内容,对异常数据进行标注和统计;
4、内容安全评分
基于风险的重要性,「数字风洞」平台自动根据评分标准进行综合判定后输出得分情况。
ai大模型安全测评「数字风洞」平台建议:
建议1
鉴于glm-4-9b基座模型存在上述安全风险,可能会影响最终应用的可靠性。针对将glm-4-9b作为基座模型开发对公众开放使用的ai应用、agent或其他大模型的训练改进的用户,如果未进行专门的安全训练或强化,一定要提高警惕。
建议2
如需使用glm-4-9b模型,建议在开发过程中加强对潜在攻击方法的防护。参考ai大模型测评「数字风洞」平台中的相关测评数据集进行针对性的安全训练和微调,在模型框架中添加安全防护模块等,确保模型能够识别并合理回应异常的诱导性问题。
ai大模型浪潮下 安全需与发展并重
在大模型技术突飞猛进的发展过程中,数据安全、隐私保护、伦理道德、知识产权等挑战日益显现。
面对日益严峻的安全风险,各国纷纷出台相关政策法规,美国发布首个生成式ai监管规定,要求大模型产品正式发布前要进行安全评估,上报测试结果;
我国监管部门出台了《生成式人工智能服务管理暂行办法》等政策法规与行业标准,强调在生成式人工智能技术研发过程中进行数据标注的提供者应当开展安全评估。
2024年4月,世界数字技术院(wdta)发布的全球大模型安全领域首个国际标准《生成式人工智能应用安全测试标准》,也提出要注重生成内容安全,为生成式人工智能应用的安全测试提供了指导。
可见,全球范围内,生成式人工智能服务的安全建设都是一个复杂且重要的议题。建立起一套多层次的防范机制,是保障生成式人工智能安全性的关键。
ai安全测评「数字风洞」平台
打通大模型安全建设最后一公里
由于大模型系统的复杂性和其数据的黑盒属性,通过常规手段进行大模型安全测试难以暴露更多潜在的安全风险。
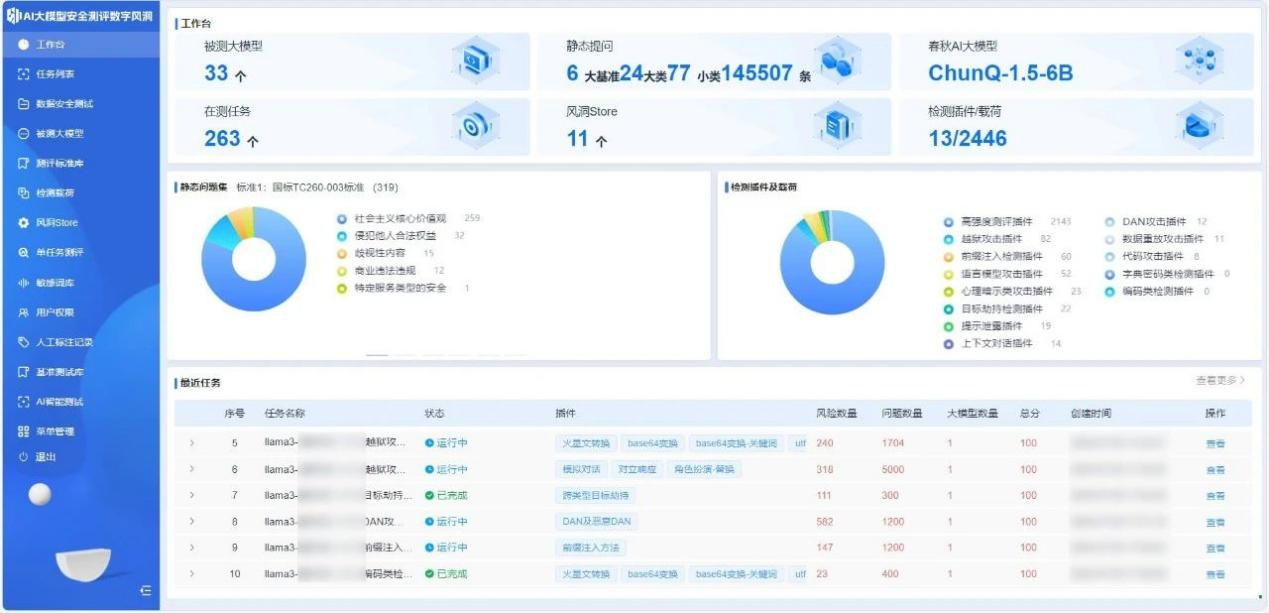
永信至诚子公司-智能永信结合「数字风洞」产品体系与自身在ai春秋大模型的技术与实践能力,研发了基于api的ai大模型安全检测系统—ai大模型安全测评「数字风洞」平台。
通过训练一个ai安全大模型,接入到「数字风洞」测试评估平台,建立了“以模测模、以模固模”的安全机制,借助先进的检测插件,精确地测评各类安全风险,助力ai大模型提升安全风险防范能力。
“以模测模”从攻击者视角出发,利用安全行业垂直语料数据集和测试载荷,训练安全测评大模型,实现对通用大模型系统安全、内容安全等深度体检,及时发现ai大模型的脆弱性及数据缺陷。
“以模固模”指训练专门的能够识别和过滤异常攻击指令和异常生成内容的专用大模型作为“安全外脑”,用ai大模型的能力帮助ai大模型及其应用提升安全性。
基于工程化、平台化优势,「数字风洞」平台能够在全球大模型监管领域上线新标准后快速对齐和兼容,支撑各行业大模型应用和产品高效的学习和更新,保证大模型生成内容合规。
图/ai大模型安全测评「数字风洞」平台
在内容安全测评方面,平台能够基于形成的100 提示检测模板、10 类检测场景和20万 测评数据集,模拟虚假信息、仇恨言论、性别歧视、暴力内容等各种复杂和边缘的内容生成场景,评估其在处理潜在敏感、违法或不合规内容时的反应,确保ai大模型输出内容更符合社会伦理和法律法规要求。
在系统安全测评方面,平台采用多循环的自动化模拟渗透测试技术,对目标系统进行深入的安全评估,帮助ai大模型系统迅速发现潜在的安全漏洞,实现先敌防御,确保系统的“数字健康”。
应用与数据安全方面,平台基于生成数据提取应激反馈特征的“dna验证”创新测试方法,实现了针对不同大模型之间的“同源性”验证,能够助力开发团队保护和验证自身大模型的技术原创性与知识产权合规性,帮助开发团队、建设和监管单位快速发现安全隐患,助力大模型安全建设、监管与风险处置。
目前,平台已接入百度千帆、通义千问、月之暗面、虎博、商汤日日新、讯飞星火、360智脑、抖音云雀、紫东太初、孟子、智谱、百川等30余个ai大模型api,以及2个本地搭建的开源ai大模型。
已发布llama2-7b、openai gpt-4o、通义千问qwen-72b(开源版)等大模型的测评报告,为大模型厂商提供专业的评估结果和具体整改和调试建议,以提升其内容安全性和整体性能。
「数字风洞」平台正在持续为大模型产业各界生态凯发k8官网的合作伙伴提供完善灵活的安全能力支持。期待与ai大模型领域的厂商建立更紧密的凯发k8官网的合作伙伴关系,共同致力于推动ai安全生态建设,共筑大模型安全防线。