继高考之后,各地中考也陆续落下帷幕。之前,多家机构和媒体用高考题评测大模型们的“高考成绩”,吸引了不少眼球。那面对中考题,尤其是大模型不太擅长的数学科目,又会有怎样的结果呢?
让我们以今年北京中考数学试卷为例,再测一下大模型们的答题实力吧!
今天的测试“选手”分别是国产九章大模型和gpt-4o大模型。九章大模型(mathgpt),是学而思自主研发,面向全球数学爱好者和科研机构,以解题和讲题算法为核心的大模型。此前在matheval排行榜多个维度的评测中都排名第一。gpt-4o是由openai公司研发,是国际上备受关注的大语言模型之一,除了自然语言处理,gpt-4o还具备一定的推理能力,能够处理需要逻辑分析和判断的问题。
究竟谁在这场“数学比拼”中更胜一筹,让我们一起看看。
一、先说结论
本次测试选择了2024年北京中考数学试卷中的17道题,分别是8道选择题、8道填空题以及1道解答题。
在测试题目的比拼中,九章大模型的正确率为85%,gpt-4o的正确率为75%。
【九章大模型(mathgpt)】
选择题8题,做对5题。
填空题8题,做对6题。
九章大模型总分 = 5 * 2分 6* 2分 1分 = 23分 (满分30分)
【gpt-4o】
选择题8题,正确5题。
填空题8题,正确5题。
gpt-4o总分 = 5* 2分 5* 2分 = 20分 (满分30分)
注:填空题的最后一题有两问共2分,答对一问记1分。
在这次ai比拼中,九章大模型凭借其在数学领域的专业优势,取得了较高的正确率。这表明在特定领域,尤其是数学解题,定制化的大模型能够展现出更强的性能。然而,两者在复杂图题上的表现都存在不足,说明在这类问题的逻辑推理和步骤展示上,ai仍有待提升。
从教育的角度看,ai大模型为学习者提供了及时反馈和考点解析,有助于增强学习体验和深度理解。但同时,ai的局限性也提醒我们,它目前还不能完全替代人类教师的角色,尤其是在精细化指导和情感交流层面。
未来,ai与教育的结合可能会推动教学模式的创新,如人机协同教学以及自适应学习路径等。要实现这些愿景,ai技术需要在保证准确性和普适性的同时,进一步增强其在复杂情境下的理解和应用能力。
二、测试方法
1、测试题目:2024年北京中考数学试卷选择题的第1-8题,填空题的第9-16题,解答题第26题。
2、由于数学解答题的评估涉及复杂的推理步骤和逻辑判断,直接评判模型答案的正确性较为困难。因此,本次测试的重点放在了选择题和填空题上,这些题目通常有明确的正确答案,便于公正地评估模型的解答能力。
三、选择题,难分伯仲
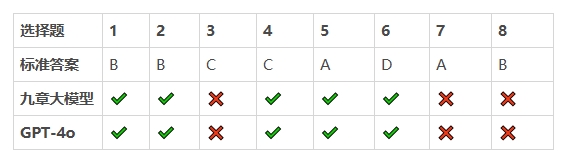
以一道经典的概率推论题为例,一起来看一下二者的分析过程
九章大模型如下作答:

gpt-4o分析思路:

四、填空题,九章大模型获胜
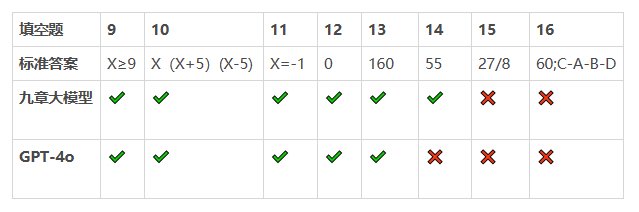
第14题,gpt-4o回答错误
九章大模型正确解答:

gpt-4o的分析过程:

第16题,均出现错误
九章大模型只答对了第一问,其分析过程:

gpt-4o两问均回答错误,其解答过程:
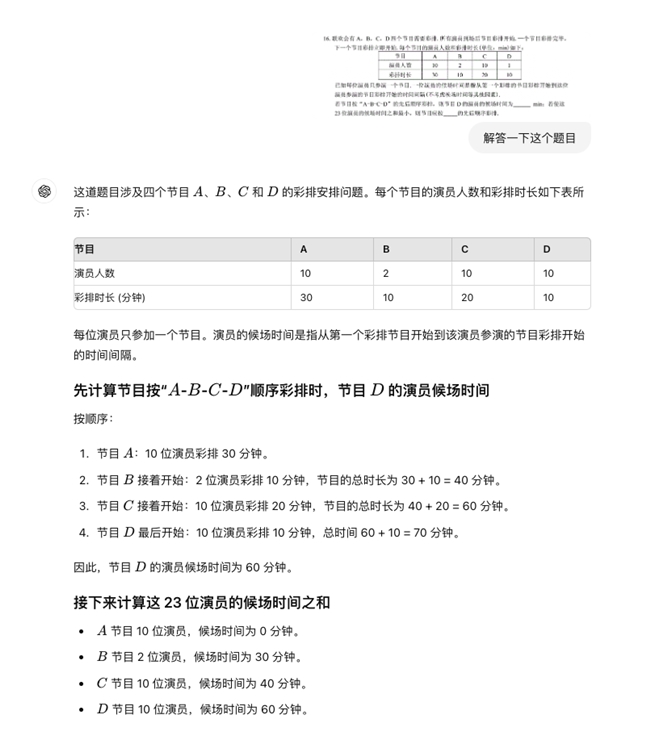

五、解答题
第26题,九章大模型最终答案正确。
九章大模型的分析过程:

gpt-4o最终答案有误,其分析过程:
